Evidencing the need to move to Specificity, and move on from Sufficiency by Regional Care Cooperatives
Extracts from
How do we construct knowledge about people’s lives, and who has the power to tell the stories that count (or are counted)?
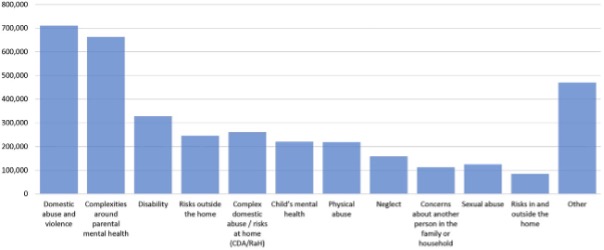
The findings show that it is possible to categorise demand for Children’s Social Care in England using the factors identified in social work assessments. Quantitative analysis of a large national data-set yielded twelve latent classes that were found consistently both over time and across different LAs (see diagram below).
There are potential applications for operational and planning purposes, as well as for understanding how risk and need are conceptualised and acted on by children’s services.
Since these categories derive from the risk factors identified by social workers, they are explicitly linked to the professional and institutional priorities of child welfare agencies. As Hood et al. (2021) point out, this makes them a valuable evidence-based tool for planning and designing services. Unlike aggregate figures on provision, they are informative about the range of problems that agencies are required to address. In contrast to crude labels such as the ‘toxic trio’, they are also sensitive to the multiplicity of needs experienced by children whilst offering a degree of nuance and differentiation.
The importance of using Latent Class Analysis by Regional Care Cooperatives in creating needs-led specificity
Services wishing to study their own demand using these categories are welcome to use the template and code made available in the Supplementary Material to this article
LCA aims to identify mutually exclusive and distinct sub-groups within a population based on patterns of responses in observed variables (Hagenaars and McCutcheon, 2002). The purpose of LCA is to derive a categorical variable that cannot be directly observed, but can be inferred from a combination of ‘indicator variables’, which can be observed. A latent class model estimates two main sets of parameters: the latent class frequency, which is the estimated probability that individuals belong to a particular latent class, and the conditional item probabilities (sometimes called ‘indicator probabilities’), which describe the relationships between observable indicator variables and a finite number of latent class clusters. These probabilities are estimated via a process of iteration and convergence using maximum-likelihood estimation (McCutcheon, 1987). There are three main stages to carrying out a latent class model: first, the indicators to be included in the model must be selected, second, the number of latent classes must be chosen and last, the validity and reliability of the model must be assessed to ensure the model accurately represents the data. At each step, ‘fit indices’ can be used to inform the process of identifying an appropriate model (Nylund et al., 2007).